Linear regression could not yield proper result in classification Problem, because outliers could affect the result.
Logistic Regression is still a classification algorithm, even though it is called regression.
Hypothesis Function
Logistic regression uses the “Sigmoid Function” (or “Logistic Function”) as hypothesis function:
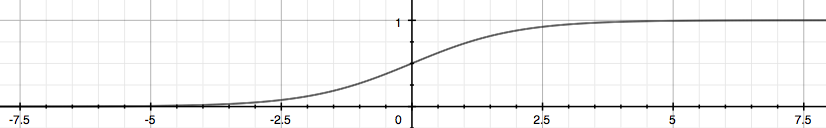
will give us the probability that our output is 1.
Decision Boundary
Decision boundary is on , also
It is a feature of the trained model (parameters).
Non linear decision boundaries:
Just create new features to fit.
Cost Function
$
J(\theta) = \frac{1}{m} \sum_{i=1}^m \mathrm{Cost}(h_\theta(x^{(i)}),y^{(i)})
$
Vectorized version:
Why not Using Squared Error?
If using squared error on sigmoid function, it will be non-convex, so that we can’t use gradient descent.
Optimization
Derivative for Gradient Descent
It looks identical to linear regression
$
\frac{d}{d\theta_j}J(\theta)=\frac{1}{m}\displaystyle\sum_{i=1}^m{(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_j}
$
$
J(\theta_0,\theta_1,\theta_2, …) = \frac{1}{m}\displaystyle\sum_{i=1}^m{Cost(h_\theta(x^{(i)}), y^{(i)})}+\frac{\lambda}{2m}\displaystyle\sum_{j=1}^n{\theta^2_j}
$
( is regularization parameter)
Update :
$
\theta_j = \theta_j -\frac{\alpha}{m}\displaystyle\sum_{i=1}^m{(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_j}
$
Vectorized implementation: